Introduction :
Most people never think about what happens behind the scenes when they open an app, shop online, watch a video recommendation, or track a delivery in real time.
But in reality, thousands—or even millions—of pieces of data are moving every second.
Orders are being processed.
Payments are being verified.
Notifications are being sent.
Analytics dashboards are updating live.
And the thing quietly managing all of this is often a TD pipeline.
That’s why TD Pipeline Development has become such an important part of modern technology. Businesses today don’t just need data. They need systems that can move data smoothly, process it quickly, and make it useful in real time.
If that sounds technical, don’t worry.
This guide is written in a simple, human way—without overwhelming jargon. Whether you’re a beginner, developer, business owner, or just curious about how modern systems work, this article will help you understand TD pipeline development in a practical and realistic way.
What is TD Pipeline Development? :
Let’s keep this simple.
TD Pipeline Development is the process of building systems that move data from one place to another automatically.
But it’s not just about moving data.
A good pipeline also:
- Cleans the data
- Organizes it
- Processes it
- Stores it
- Delivers it where it’s needed
Think of it like a city water system.
Water travels through pipelines to reach homes safely and efficiently.
Data pipelines work in a very similar way. Instead of water, they transport information.
Why TD Pipelines Matter More Than Ever :
We live in a world completely driven by data.
Every click, purchase, login, message, and online interaction creates information.
Now imagine trying to manage all of that manually.
Impossible.
That’s exactly why pipelines exist.
They help businesses:
- Save time
- Reduce mistakes
- Automate processes
- Handle massive amounts of data
- Make faster decisions
Without pipelines, modern apps and digital services would struggle to function properly.
A Simple Real-Life Example :
Let’s say you order shoes from an online store.
Seems simple, right?
But behind that single order, a lot happens instantly.
The moment you click “Buy Now”:
- Your payment gets verified
- Inventory updates automatically
- Shipping systems receive your order
- Analytics dashboards record the sale
- Recommendation systems learn your shopping behavior
- Confirmation emails are triggered
All of this is powered by data pipelines running quietly in the background.
You never see them.
But without them, the experience would completely fall apart.
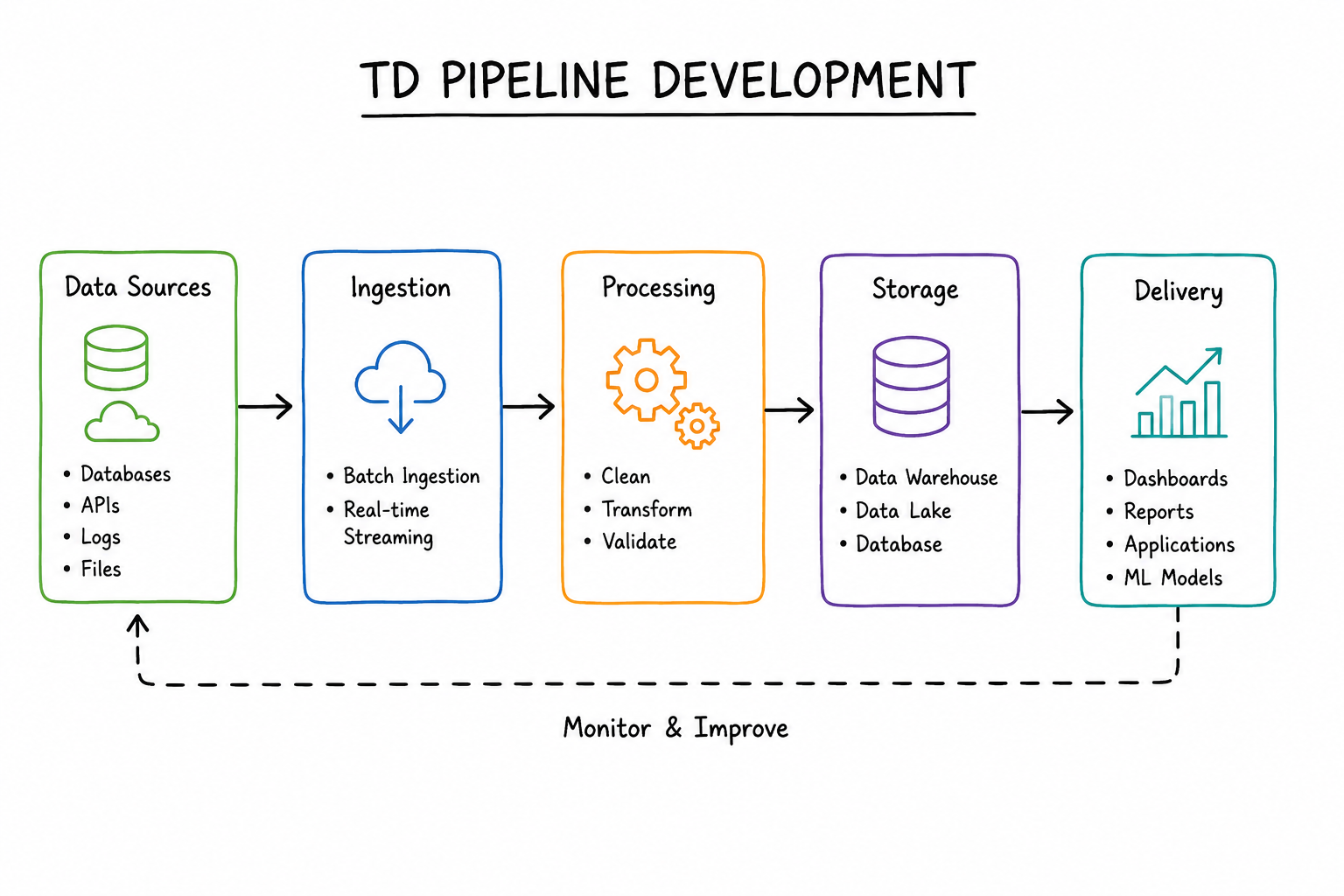
How a TD Pipeline Actually Works :
A pipeline usually moves through several stages.
Let’s break them down in the easiest way possible.
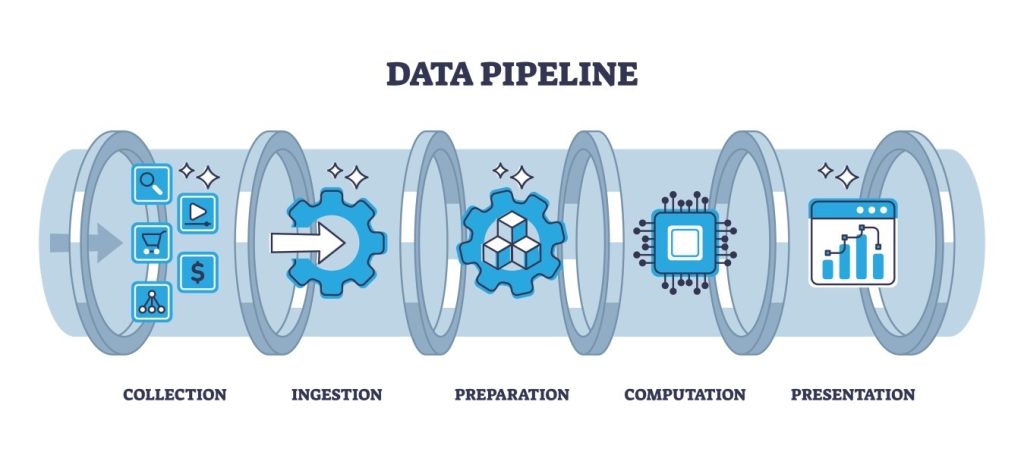
1. Data Collection :
Everything starts with collecting data.
Data can come from:
- Websites
- Apps
- APIs
- Databases
- Cloud platforms
- IoT devices
For example:
A fitness app collects steps, heart rate, and workout activity.
That information becomes the raw input for the pipeline.
2. Data Ingestion :
This is the stage where data enters the system.
There are usually two approaches.
Batch Processing :
Data is collected and processed at intervals.
Example:
A company generating daily sales reports every night.
Real-Time Processing :
Data moves instantly as it’s created.
Example:
Live GPS tracking or stock market updates.
Real-time pipelines are becoming increasingly popular because businesses want immediate insights.
3. Data Processing :
Raw data is usually messy.
Some records may be incomplete.
Some may have duplicates.
Some may contain errors.
This stage cleans and transforms the data into something useful.
Typical tasks include:
- Removing duplicate entries
- Fixing formatting issues
- Filtering invalid records
- Organizing information
This step is extremely important because poor-quality data leads to poor decisions.
4. Data Storage :
Once the data is cleaned, it needs to be stored safely.
Businesses often use:
- Data warehouses
- Cloud storage
- Data lakes
- Operational databases
The choice depends on:
- Speed requirements
- Cost
- Scalability
- Business goals
5. Data Delivery :
Now the data becomes useful.
It gets delivered to:
- Dashboards
- Reports
- Applications
- AI systems
- Analytics platforms
This is the stage where businesses finally gain insights.
Types of TD Pipelines :
Not every business uses the same kind of pipeline.
Different situations require different approaches.
Batch Pipelines :
Batch pipelines process data in chunks.
For example:
- Daily reports
- Weekly analytics
- Monthly summaries
Why Businesses Use Batch Pipelines :
- Easier to manage
- Lower infrastructure cost
- Good for large datasets
The Downside :
The information is delayed.
You only get updates after processing is complete.
Real-Time Pipelines :
Real-time pipelines process data instantly.
Examples include:
- Fraud detection systems
- Food delivery tracking
- Live recommendation engines
Why Real-Time Pipelines Matter :
People expect speed today.
Nobody wants to wait hours for updates anymore.
The Challenge :
Real-time systems are more complex and expensive to build.
Hybrid Pipelines :
Most modern businesses use hybrid pipelines.
They combine:
- Batch processing for heavy workloads
- Real-time processing for instant insights
This creates a balanced system.
Tools Commonly Used in TD Pipeline Development :
You don’t need to learn every tool immediately.
But understanding the ecosystem helps.
Programming Languages :
Python :
Probably the most beginner-friendly option for data engineering.
It’s simple, flexible, and widely used.
Java :
Popular in enterprise systems because of its performance and stability.
Scala :
Common in large-scale big data environments.
Popular Data Engineering Tools :
Apache Spark :
One of the most powerful frameworks for large-scale data processing.
Useful for:
- Big data analytics
- Real-time processing
- Distributed computing
Official website:
Apache Spark
Apache Airflow :
Helps automate workflows and schedule pipelines efficiently.
Official website:
Apache Airflow
Amazon Web Services :
Provides scalable cloud infrastructure for pipelines.
Official website:
AWS Big Data Services
Google Cloud Platform :
Popular for analytics and AI-based data systems.
Official website:
Google Cloud Data Pipelines
Step-by-Step Process of Building a TD Pipeline :
Now let’s make this practical.
Step 1: Understand the Problem :
Before writing code, ask:
- What data do we need?
- Why are we collecting it?
- What business problem are we solving?
This step is often overlooked, but it matters the most.
Step 2: Choose the Right Architecture :
Decide whether your system needs:
- Batch processing
- Real-time processing
- Hybrid architecture
Not every project needs a complex real-time setup.
Step 3: Connect Data Sources :
Your pipeline needs reliable access to data sources like:
- APIs
- Databases
- Applications
- Third-party systems
Step 4: Transform the Data :
This is where raw information becomes meaningful.
You clean it.
Organize it.
Validate it.
Good transformation leads to trustworthy insights.
Step 5: Store Data Properly :
Storage decisions affect:
- Performance
- Cost
- Scalability
Planning ahead saves future headaches.
Step 6: Automate Everything :
Manual workflows eventually become painful.
Automation tools like Apache Airflow help pipelines run consistently without constant human intervention.
Step 7: Monitor the Pipeline :
Even good pipelines fail sometimes.
Servers crash.
Connections drop.
Data formats change.
Monitoring helps catch problems early before they become disasters.
Common Challenges in TD Pipeline Development :
Nobody talks enough about the difficult parts.
Building pipelines sounds exciting until real-world problems appear.
Dirty Data :
Bad input data is one of the biggest problems in data engineering.
Even powerful systems fail when data quality is poor.
Scaling Issues :
A pipeline that works for 1,000 users may struggle with 1 million users.
Scalability always becomes important eventually.
Integration Complexity :
Different systems often speak different “languages.”
Connecting them smoothly can be difficult.
Cost Management :
Cloud infrastructure can become expensive very quickly if pipelines are poorly optimized.
Why TD Pipelines Are Important for AI :
Artificial Intelligence depends heavily on data.
But AI models are only as good as the information they receive.
That’s where pipelines become essential.
They help:
- Gather training data
- Clean datasets
- Deliver features to models
- Process predictions in real time
Without pipelines, modern AI systems would not function efficiently.
Future of TD Pipeline Development :
The future is moving toward faster, smarter, and more automated systems.
Here’s what’s coming next.
Real-Time Systems Everywhere :
Businesses increasingly expect instant insights.
Real-time pipelines will continue growing rapidly.
AI-Powered Automation :
AI tools are beginning to automate pipeline optimization and monitoring.
Serverless Data Engineering :
Less infrastructure management.
More focus on development.
Data Mesh Architecture :
Teams manage their own pipelines independently instead of relying on one centralized system.
Internal Linking Ideas :
To improve SEO and user engagement, internally link this article to related topics like:
Internal links help users explore more content while improving website structure.
External Resources :
Useful resources for deeper learning:
- Python Documentation
- Apache Spark Official Site
- Apache Airflow Documentation
- AWS Big Data Solutions
- Google Cloud Data Pipelines
Rich Media Suggestions :
Adding visuals makes technical blogs far easier to understand.
Recommended Images :
- TD pipeline architecture infographic
- Real-time data flow diagrams
- Cloud pipeline workflow illustrations
Recommended Videos :
- Beginner’s guide to data engineering
- How real-time pipelines work
- Introduction to Apache Spark
Frequently Asked Questions (FAQ) :
What is TD pipeline development? :
It’s the process of building systems that automatically collect, process, store, and deliver data efficiently.
Is TD pipeline development hard for beginners? :
It can feel overwhelming initially, but starting with small projects makes the learning process much easier.
Which programming language is best for beginners? :
Python is usually the best starting point because it’s simple and widely used.
What is the difference between batch and real-time pipelines? :
Batch pipelines process data at scheduled intervals, while real-time pipelines process information instantly.
Are pipelines important for AI systems? :
Yes. AI systems depend on pipelines to receive clean and organized data.
Final Thoughts :
TD Pipeline Development may sound highly technical at first, but at its core, it’s really about solving one important problem:
Making data useful.
Modern businesses survive on information.
Pipelines help move that information efficiently, reliably, and intelligently.
The best way to learn is not by memorizing definitions.
It’s by building.
Experimenting.
Breaking things.
Fixing them.
And slowly understanding how data flows through systems.
That’s how real growth happens in tech.
☎️ 919967940928
🌐 https://aibuzz.net/